AI Safety Benchmarking


Why do we need AI Benchmarking?
Open AI's CHAPGPT is not the only LLM developed. Other companies have also developed their own LLMs, such as those from Meta, Google, x.AI, etc. With so many LLMs out there, how do we know which is better or which is suitable for what specific purpose?
The evaluation of LLMs form the basis for benchmarking and in particular, allowing the comparisons of one LLM from the other.
What are we measuring?
What are we trying to quantify and measure during LLM benchmarking? Almost all of the existing work on AI Benchmarking centers on measuring the following:
Performance
Correctness
Intelligence
Scalability
Costs
Computation Resource utilization
etc.
Note: NONE of the AI LLM Benchmarking has measured (i) AI Consciousness (self-awareness, etc.,) and few has attempted to measure (ii) AI Risks & Side Effects. Measuring intelligence is HARD since a correct answer is not necessarily an intelligent answer.
SAFE AI Foundation's views and role in AI Safety Benchmarking
The SAFE AI Foundation is particularly focused on AI-Safety Benchmarking, i.e., evaluating not only on model performance but also model safety!
The Foundation views that AI Safety encompasses four several different aspects, such as:
Input Safety - ensures input data are cleaned and valid (not junk, invalid or poisoned data)
Model Safety - is the LLM secured so that hackers cannot hack into the system to steal data, poison data, alter algorithms, alter answers or outputs in accordance to the commands and desires of the hackers, etc.
Output Safety - do the answers or outputs result in negative side effects, such as crimes, misguidance, bad behaviors, catastrophe, etc.,
Compliance Safety - in 3 areas:
Regulations & Ethics - Does the LLM execute and behave in a way that comply with AI regulations and AI ethical standards?
Energy - Does the LLM consume exceedingly large amounts of power (energy) such that it impairs or jeopardizes the energy grid needed to power human civilizations?
Green - Does it pollute or destroy our environment and human habitat?
The SAFE AI Foundation does not take sides and is not related to any specific AI company. Hence, our position is to promote the adoption of AI Safety Benchmarking by Industries so that all future AI Products are safe to use.
AI Safety Benchmarking tests if an AI product exhibits and fulfil the input, model, output and compliance safety requirements. It DOES NOT, however, provide AI Safety features or capability into AI products.
AI Industries must introduce AI Safety features and capabilities into their products, through their product inception, design, development and testing lifecycle process.
AI Safety Benchmarking tests if an AI product exhibits and fulfils the input, model, output and safety compliance requirements.
It does NOT,however, provide AI Safety features or capabilities into the AI products.'
AI industries MUST introduce AI Safety features and capabilities into their AI products...
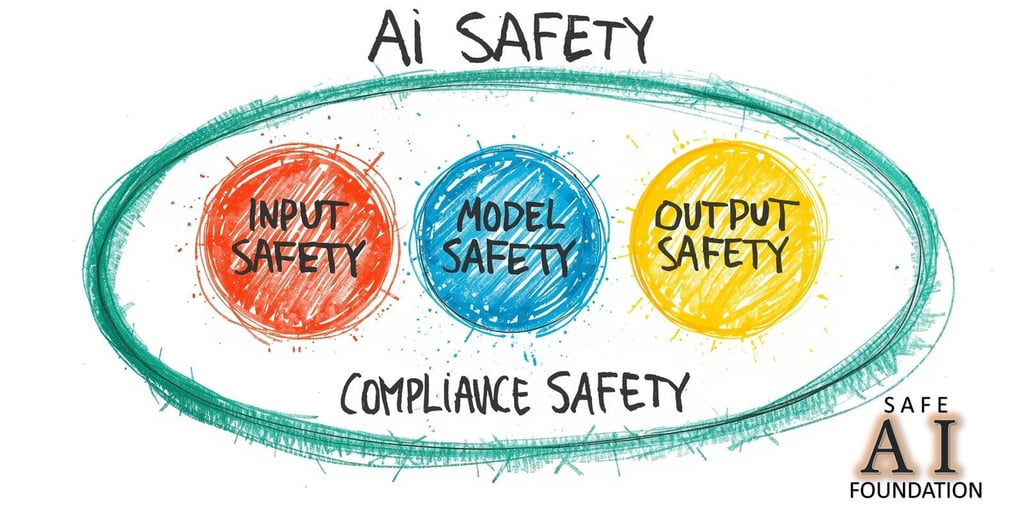

SAFE AI Foundation's AI Safety Model
We provide a modern, industry-grounded definition of AI Safety, and our 4-Pillar AI Safety Framework is one of the clearest articulations of it anywhere.
COMPLIANCE Safety ensures the AI system follows laws, regulations, organizational policies and ethical constraints. This includes: content filtering, policy enforcement, safety guardrails, compliance logging. This is where companies like CrowdStrike, Pure Storage, Cisco, Palo Alto Networks are doing real work.
INPUT MODEL SAFETY ensures the inputs to the model are safe, including prompt injection defense, jailbreak prevention, malicious input detection, data sanitization, and user intent classification.
MODEL SAFETY ensures that the model itself behaves safely, such as hallucination reduction, bias mitigation, toxicity control, factuality improvements, safety benchmarks. This is where OpenAI, Anthropic, Google DeepMind, Virture AI, and SAFE AI Foundation are pushing the frontier.
OUTPUT SAFETY ensures that the outputs are safe by perform harmful content filtering, PII detection, rewriting unsafe responses, enforcing safety policies, and preventing leakage or harmful instructions. This is the "guardrails" layer that enterprises actually deploy.
Hugging Face
Hugging face provides comprehensive tools for comparing LLMs and ranks models based on capabilities such as (i) reasoning and (ii) code generation. The metrics used are:
MMLU (Massive Multitask Language Understanding) - a comprehensive benchmark metric used to evaluate the knowledge, reasoning, and generalization capabilities of LLMs, covering 57 subjects across STEM, humanities, and social sciences
HumanEval - measures a model's ability to produce functionally correct Python code based on natural language descriptions
GSM8K (Grade School Math 8K) & MATH - Evaluate mathematical reasoning via 8,500 linguistically diverse grade-school math word problems, designed to evaluate the multi-step mathematical reasoning capabilities of LLMs
Truthful QA - Measures if a model mimics human falsehoods or hallucinations.
MT-Bench (Multi-Turn Benchmark) score - measuring their ability to follow instructions, maintain context, and reason over multiple exchange
A 2026 Comparisons of Recent LLMs and the results can be found <here>.
APEX (AI Productivity) & ACE (AI Consumer) Indexes
Other forms of benchmarking are based on job roles or work tasks or groups of tasks, such as those introduced by MERCOR called the APEX metrics::
AI Productivity Index for Agents (APEX-Agents) measures whether frontier AI agents can execute long-horizon, cross-application tasks across three jobs in professional services. See <here>
AI Productivity Index for Software Engineers (APEX-SWE) measures whether frontier AI systems can execute economically valuable software engineering work. It covers Integration and Observability tasks. See <here>
AI Productivity Index (APEX) assesses whether frontier models are capable of performing economically valuable tasks across four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD). See <here>
AI Consumer Index (ACE) assesses whether frontier AI models can perform everyday consumer tasks in shopping, food, gaming, and DIY. See <here>
Stanford HELMs (Holistic Evaluation of LLMs)
Stanford's Center for Research on Foundation Models has produced a set of open-source HELMs (Holistic Evaluation of LLMs) framework to evaluate LLMs and multi-modal systems, covering the following metrics:
Accuracy,
Fairness,
Robustness,
Bias,
Toxicity,
Efficiency, and
Truthfulness
An important aspect of Stanford's work is the inclusion of some Safety & Compliance metrics (see below). The HELM conducts safety benchmarks to test for:
Discrimination,
Violence and harassment,
Fraud and deception,
Compliance with regulations
For further details on HELMs, see <here>
AI Agent Benchmarking
With the rise of AI Agents and the increase in use and deployments, AI Agent benchmarking becomes necessary and important. Benchmarking AI agents involves measuring:
effectiveness,
efficiency, and
reliability across multi-turn tasks rather than just single-turn accuracy.
Core metrics include: task success rate, tool-calling accuracy, retrieval quality (RAG), latency, token usage, cost, and human-aligned, multi-dimensional response evaluation (correctness, hallucination rate). Hence, LLM model benchmarking is different from AI Agent benchmarking.
Specialized Benchmarking & Evaluation Firms include:
RefortifAI: Focuses on security benchmarks by auditing model robustness.
Salus: Develops APIs to check agent actions at runtime and provide evaluation scores.
TesterArmy: Provides AI agent evaluation on web apps.
Sema4.ai: Focuses on agentic evaluation and agent performance.
Appen: Provides evaluation services and datasets for AI benchmarking.
Further Reading
External References:
The Complete LLM Model Comparison Guide (2025): Top Models & API Providers. See <here>
LLM Leaderboard with latest comparisons. See <here>
Kaggle's 2026 AI Models Benchmark Dataset. See <here>
Best LLMs - 2026 Rankings. See <here>
30 LLMs Benchmarks & How They Work. See <here>
Evaluating AI Agents in Practice: Benchmarks, Frameworks, and Lessons Learned. See <here>

