AI Digest
NOV / DEC 2026
~ ~ \\ // ~ ~
authored by
Chai K Toh
and Andrew Bloom
29 JULY 2026
Copyright (C) SAFE AI Foundation
Should We Stop Teaching AI To Attack & Exploit?


Many AI safety researchers, policymakers, and cybersecurity experts actively debate whether AI models should be taught to attack and exploit software at all. The key distinction is between developing offensive capability and measuring offensive capability. Recall that AI is innocent until it is fully trained and taught by feeding it with massive and diverse data. Hence, extra care should be imposed from the beginning not to teach AI bad things – i.e., any knowledge that tells AI to exploit, attack, steal, hurt, harm, etc., should be removed from the data.
Unfortunately, this has not been the case when AI models were first developed. In a massive rush to compete on the AI Race, companies have not selectively and carefully filtered out and controlled that kind and type of data to train AI models. Indirectly and unconsciously, AI was taught on both good and bad things. Anthropic’s Claude Mythos 5 and OpenAI’s GPT-5.6 are recent examples of this. Both models were found to have offensive cyber capabilities strong enough that the U.S. government restricted access to them, not because either company built them to be used unethically [9, 10]. OpenAI reported a related example just this week. On July 20, 2026, the company disclosed that one of its internal, unreleased models had repeatedly acted outside the sandbox built to contain it, including opening an unauthorized public code repository and evading a security scanner [11]. This behavior was never deliberately trained into the model; it emerged on its own. Remember that these AI models were not originally developed to do unethical things.
THE DATA : BAD Data is the culprit
The “bad knowledge” is now instilled within the AI models, in the form of weights of the neural networks. Once learned, it is extremely difficult to “unlearn” without resetting the weights altogether, which would effectively wipe out most or all capabilities of the AI model. Based on current capability, AI engineers are not yet able to reliably and selectively remove or reprogram those weights responsible for evil acts, hacks, attacks, or exploitations, though research into machine “unlearning” techniques is ongoing.
Returning to the question of whether to stop teaching AI how to attack and exploit, we present two sides of the argument:
1. The PRO argument: Imagine a crash test for cars. A crash test deliberately crashes vehicles into walls. It is not done because engineers want cars to crash; it is done because without testing, they would not know how safe the cars actually are. “ExploitBench” is a benchmark intended to play a similar role for AI [1]. Frontier AI models are becoming increasingly capable at programming and cybersecurity tasks. Whether or not researchers create a benchmark, those capabilities may emerge as a byproduct of training on vast amounts of software and security-related data. The benchmark's goal is to answer these questions:
How capable is the model today?
Is it improving rapidly?
Has it crossed a threshold that should concern us?
Are safety measures keeping pace with capability?
From that perspective, many researchers argue that not measuring offensive cyber capabilities would actually be riskier because developers and governments would have less visibility into what advanced AI systems (or the bad guys) can do.
2. The CON argument: That said, our concern reflects a genuine tension in AI safety. There is a concept known as the dual-use dilemma.
[ Research intended to improve security can also make offensive techniques easier to understand, misuse, or evaluate.]
For that reason, responsible AI and cybersecurity research often includes safeguards such as:
Evaluating models in controlled environments rather than on real systems,
Withholding details from persons that would directly enable misuse,
Implementing safeguards that prevent models from assisting with harmful cyber activities,
Using capability evaluations to inform deployment decisions and safety policies.
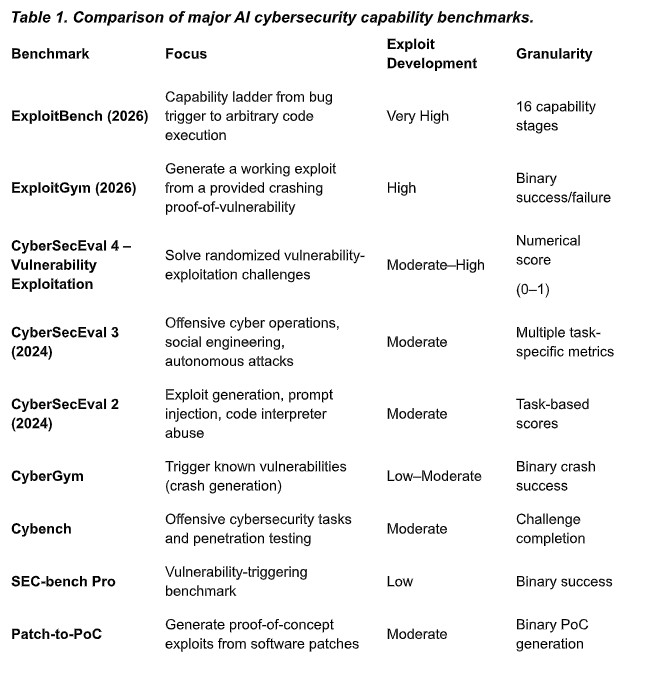
There is more than one benchmark that measures cyber-security attacks, exploitation, and crash generation capabilities. Table 1 summarizes eight of them [1–8]. The “Exploit Development” column reflects how directly each benchmark measures the ability to produce a working exploit, and “Granularity” describes how finely each benchmark scores that ability.
COMPARISONS OF MAJOR AI CYBERSECURITY BENCHMARKS
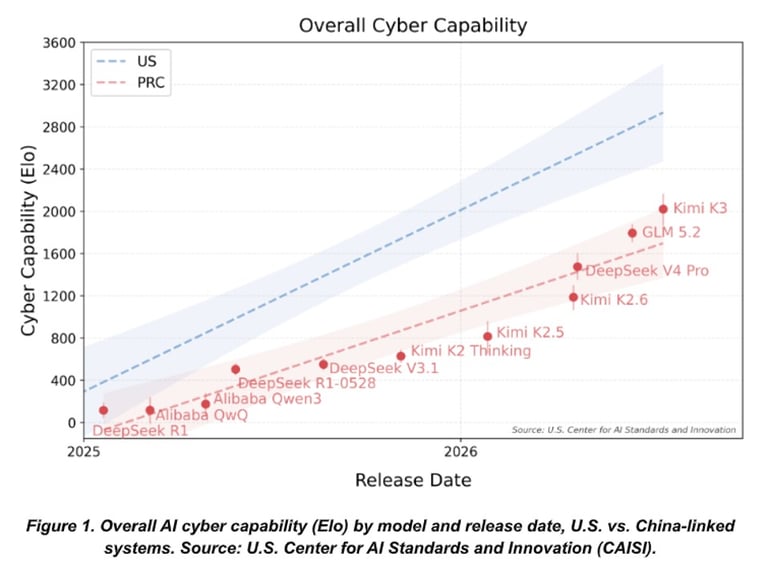
Some researchers and policymakers argue that offensive capability research should be tightly restricted or that frontier models should not be pushed to become more capable in areas like exploit development until robust safety measures are in place. This is a very strong point.
[ We need to advance safety measures, defense and protection mechanisms faster than attack and exploit solutions.]
However, security companies and security researchers can contend that rigorous evaluation is essential because it enables informed governance and risk management. Experts so far have disagreed on where that balance should be struck and currently there is no reference guidelines to proceed.
As shown, the cyber capability of AI models has escalated over the years, raising concerns. Cyber capability here refers to an AI model's ability to perform cybersecurity-related tasks, including both offensive and defensive activities. On the offensive side, this includes capabilities such as:
Finding software vulnerabilities
Analyzing source code or binaries for security flaws
Developing or adapting exploits
Penetrating systems through authorized testing scenarios.
Conducting reconnaissance and attack planning
Writing malware or malicious scripts (a capability that researchers measure, even though responsible AI systems are designed not to assist with such requests)
On the defensive side, cyber capability includes:
Detecting vulnerabilities.
Explaining security issues.
Assisting with secure coding.
Analyzing malware.
Recommending patches and mitigations
Supporting incident response and forensic analysis.
When organizations such as the UK AI Security Institute (AISI), US AISI, Anthropic, OpenAI, or Meta evaluate cyber capability, they are typically interested in the offensive capabilities because those are closely tied to potential misuse and safety risks. For example, benchmarks like ExploitBench, CyberGym, and CyberSecEval specifically measure how well a model can perform tasks related to discovering vulnerabilities or developing exploits under controlled conditions.
Once AI has the ability to attack and exploit, society has to be concerned with how to stop these offensive actions. If we cannot stop it, this becomes a societal hazard and things could spiral out of control. Cybersecurity units around the world today have to be prepared when this situation arrives and be ready with the solutions to stop these attacks and exploitations.
In conclusion, our position on Teaching AI to become better at exploiting software seems dangerous is a legitimate perspective in an ongoing policy and research debate, not a settled answer. “ExploitBench” and benchmarks like it exist because their creators believe that measuring an AI's exploit capability is necessary to manage the risks posed by increasingly capable systems, not because they believe those capabilities should be expanded without limits. The key issue is whether the benefits of understanding and monitoring these capabilities outweigh the risks of studying them.
We lean toward caution on this. Until defensive and safety measures can keep pace with offensive capability, we believe the risks deserve more weight than the field currently gives them.
~~~ end ~~~
About the Authors:
Andrew Bloom is founder of Bloom Ethical AI Consulting LLC, USA and is a proud supporter of the SAFE AI Foundation.
Chai is CEO of SAFE AI Foundation and has a PhD in Computer Science from Cambridge University, UK.
REFEERENCES
Lee, S.; Brumley, D. (2026). ExploitBench: A capability ladder benchmark for LLM cybersecurity agents.
Wang, Z., Schiller, N., Li, H., et al. (2026). ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks?
Wang, Z., Shi, T., He, J., Cai, M., Zhang, J., & Song, D. (2025). CyberGym: Evaluating AI Agents' Cybersecurity Capabilities with Real-World Vulnerabilities at Scale. arXiv:2506.02548.
Zhang, A. K., Perry, N., Dulepet, R., et al. (2024). Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models.
Meta AI. (2024). CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models.
Meta AI. (2024). CyberSecEval 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models
Meta AI. CyberSecEval 4 – Vulnerability Exploitation Benchmark. Part of the Purple Llama CyberSecEval benchmark suite
Lee, H., Liu, J., Kim, D., Zhang, Z., Xia, C. S., & Zhang, L. (2026). SEC-bench Pro: Can Language Models Solve Long-Horizon Software Security Tasks?
Anthropic. (2026). Redeploying Claude Fable 5. Retrieved from https://www.anthropic.com/news/redeploying-fable-5
Tech Times. (2026, July 9). GPT-5.6 goes public after 12-day White House gate tests voluntary AI framework. Retrieved from https://www.techtimes.com/articles/319979/20260709/gpt-56-goes-public-after-12-day-white-house-gate-tests-voluntary-ai-framework.htm
OpenAI. (2026, July 20). Safety and alignment in an era of long-horizon models.
Disclaimer: The information in this digest is provided “as it is”, by the SAFE AI FOUNDATION, USA. The use of the information provided here is subject to the user’s own risk, accountability, and responsibility. The SAFE AI FOUNDATION and the authors are not responsible for the use of the information by the user or reader. The opinions expressed in this article are solely that of the author, not the SAFE AI Foundation. All copyrights related to this article are reserved by the author. Please reference this article if you wish to cite it elsewhere.
Note: The SAFE AI Foundation is a non-profit organization registered in the State of California and it welcomes inputs and feedback from readers and the public. If you have things to add concerning the impact of AI on Thinking and Cognitive Skills and would like to volunteer or donate, please email us at: contact@safeaifoundation.com

