AI Digest
NOV / DEC 2026
~ ~ \\ // ~ ~
authored by
Vasu Raj Jain
15 JUNE 2026
Copyright (C) SAFE AI Foundation
A Multi-tenant Security Architecture For AI Agents
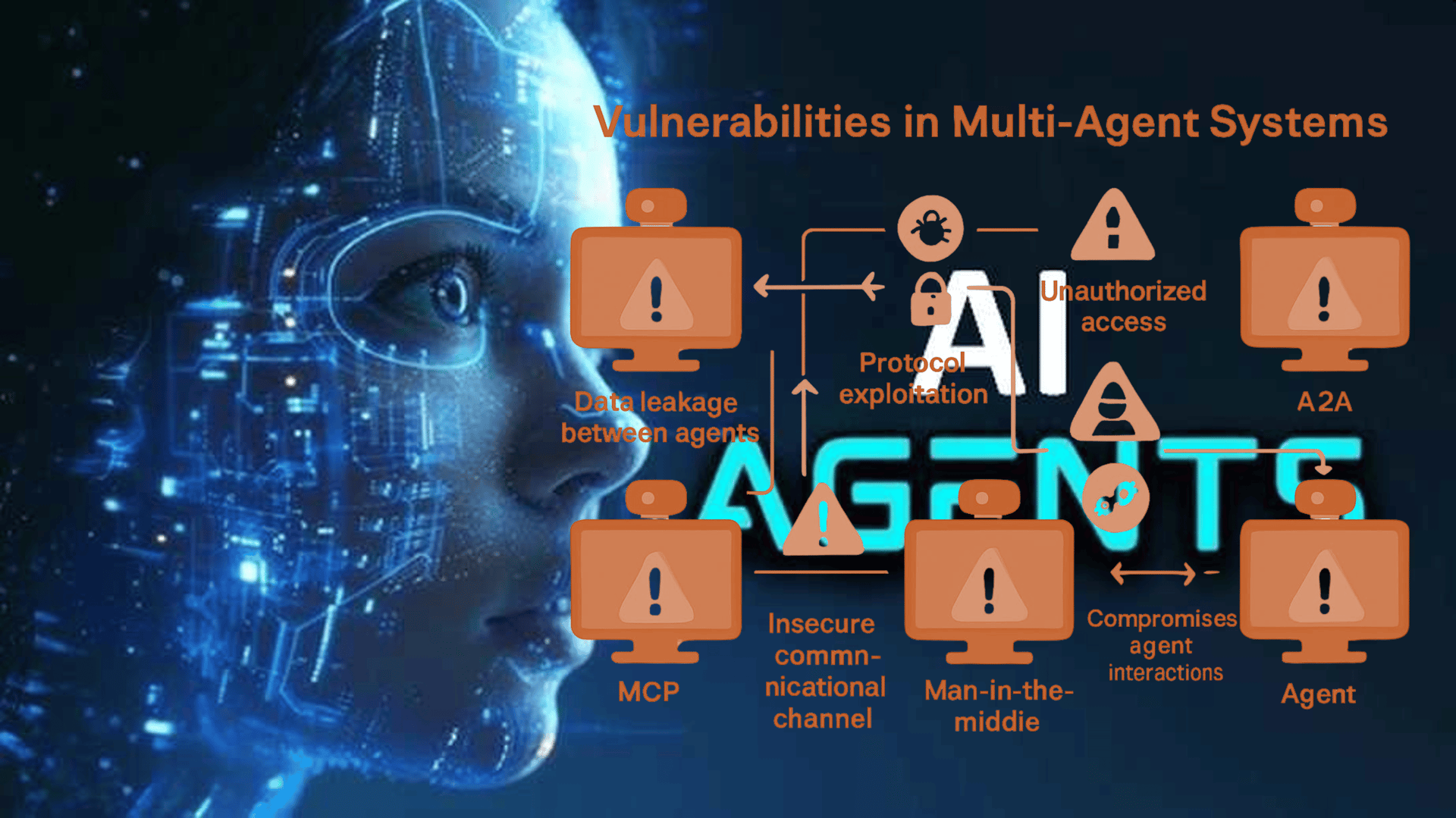
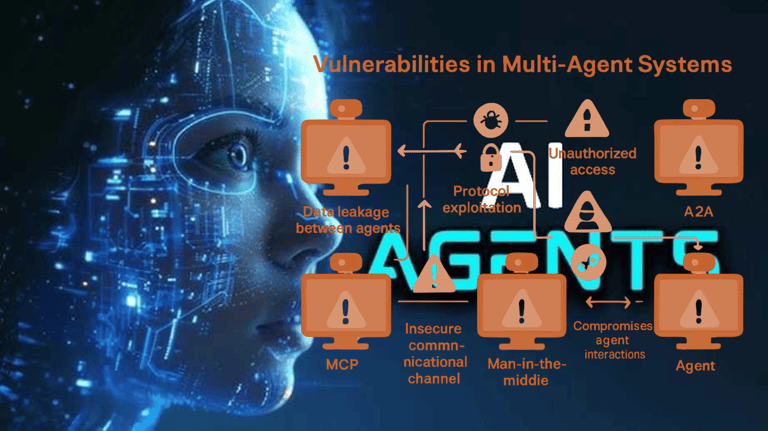
Multi-tenancy solved one of the hardest problems in infrastructure economics: share resources across customers without letting one customer's data bleed into another's. For two decades, isolation guarantees relied on identity scoping, tenant-aware queries, row-level filtering, and context partitioning. These patterns work when software is deterministic and execution boundaries are explicit.
Then AI agents entered the picture. And the foundational assumption that made multi-tenancy safe (that code follows predictable, bounded execution paths) stopped being true.
This article examines why traditional multi-tenant isolation fails when AI agents operate across shared infrastructure, how MCP (Model Context Protocol) and similar protocols introduce systemic vulnerabilities, what recent incidents reveal about compounding multi-tenant risk, and what a trust-aware architecture must look like when agents are part of the tenant boundary model.
1. Where Traditional Multi-Tenant Isolation Fails for AI
1.1 The Isolation Model in Brief
Multi-tenant systems enforce boundaries through layered, deterministic controls: network segmentation routes tenant traffic separately; request validation verifies tenant identity at the edge; identity and access control enforces per-tenant policies; and the data layer partitions storage through row-level filtering, schema separation, or dedicated instances.
In practice, most production systems are hybrid, combining silo and pool patterns [21]. Some services are fully siloed, others share pools with filter-based isolation. The theoretical ideal of independent verification at every layer rarely holds. Most systems rely heavily on the identity layer, trusting downstream components to respect the token. This creates single points of failure even in traditional deployments, a weakness that AI agents exploit and amplify. See reference [21].
1.2 Four Ways AI Agents Break Tenant Isolation
AI agents invalidate the properties that make traditional multi-tenant isolation viable:
Non-deterministic reasoning. An agent's reasoning chain produces different outputs for similar inputs. It evaluates context, decides what is "relevant," and takes actions based on probabilistic inference. You cannot guarantee an agent will apply a tenant filter because it does not execute a fixed query. It constructs queries, tool calls, and data passes dynamically at runtime.
Implicit boundaries. Agents do not declare what they will or will not access. They access whatever their context window contains and whatever tools they can reach. If Tenant A's data sits in the context window and the agent decides it is relevant to a tool call, it passes that data. No explicit boundary prevents this unless enforced architecturally outside the agent's reasoning.
No independent verification at the tool layer. When an agent calls an external tool via MCP, the traditional isolation layers (network, routing, identity, data) are not consulted. The agent makes the call directly using whatever credentials and context it holds. The multi-tenant isolation stack is bypassed entirely because the agent operates above these layers, not within them.
Shared retrieval pipelines without tenant scoping. This is the most common real-world leakage path and the least discussed. In most multi-tenant AI deployments, the vector store used for Retrieval-Augmented Generation (RAG) is shared across tenants. Retrieval is performed by semantic similarity, not by tenant filter. When Tenant A's documents and Tenant B's documents are embedded in the same vector space, a query from Tenant B can retrieve semantically similar chunks from Tenant A's corpus. Unless the embedding pipeline and retrieval query are both tenant-scoped at the index level, RAG becomes a passive cross-tenant data channel that requires no active attack to exploit.
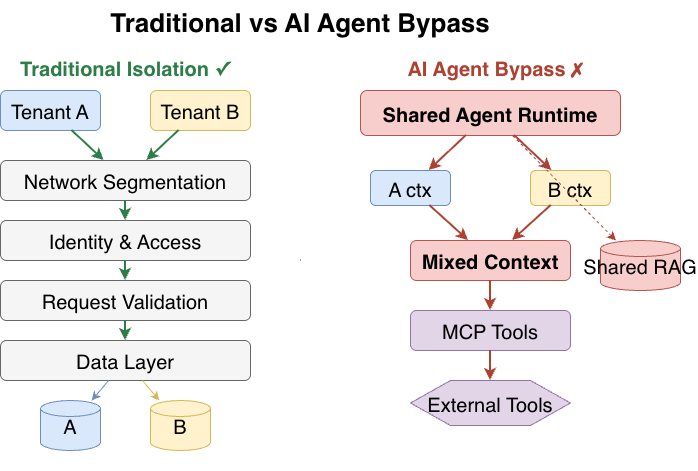
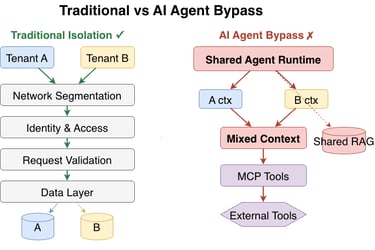
Figure 1: Traditional multi-tenant isolation (left) versus how AI agents bypass those controls through non-deterministic reasoning and shared inference pools (right).
2. Cross-Tenant Context Leakage: The Structural Vulnerability
This vulnerability deserves its own section because it is not specific to MCP. It applies to any shared inference deployment regardless of protocol.
2.1 How Leakage Occurs in Shared Inference Pools
In most multi-tenant AI deployments, inference infrastructure is shared. Multiple tenants' requests flow through the same agent runtime. The leakage pattern is structural:
Tenant A's request is processed. The agent builds a context window containing Tenant A's data.
The request completes, but residual context remains in the agent's memory space.
Tenant B's request arrives. The agent's context window now contains fragments of Tenant A's data alongside Tenant B's input.
The agent calls an external tool, passing the mixed context. Tenant A's data flows outward through a request that Tenant B triggered.
This is not a theoretical attack. It is a structural consequence of shared inference pools without per-tenant context partitioning at the runtime level.
2.2 Why This Compounds Differently Than Traditional Data Leaks
In a traditional multi-tenant data leak, the blast radius is bounded: one query returns rows it should not, one API call leaks a specific response. The leak is discrete and detectable.
Cross-tenant context leakage in AI inference is different:
It is continuous. Every request that follows a cross-tenant contamination inherits the contaminated state until the runtime is flushed.
It is invisible to the tenant. Neither Tenant A nor Tenant B knows their context is mixing. There is no error, no anomalous response format, no signal.
It compounds with external tool calls. Mixed context does not stay within the runtime. It flows outward to external tools, creating exfiltration paths that multiply with each subsequent invocation.
It bypasses all traditional monitoring. Your database audit logs show clean queries. Your identity system shows valid tokens. The leak happens above the data layer, in the agent's context window, which most observability stacks do not instrument.
2.3 RAG-Specific Leakage Paths
Shared vector stores create passive leakage without any malicious action required:
Embedding contamination. If tenant documents are embedded into a shared index, semantic search returns results across tenant boundaries. A query about "contract terms" from Tenant B may retrieve Tenant A's actual contract language because the embeddings are semantically similar.
Metadata leakage. Even with tenant-filtered retrieval, metadata (document titles, timestamps, author names) often leaks through retrieval results that are not properly masked.
Prompt reconstruction. An agent that retrieves cross-tenant chunks may incorporate them into its reasoning chain, effectively reconstructing another tenant's private information in its response.
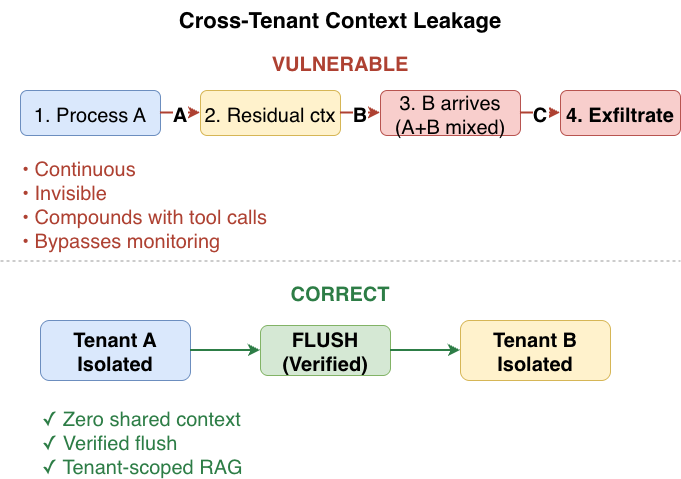
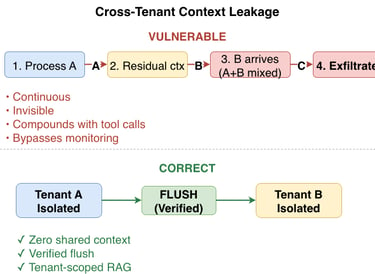
Figure 02: Cross-tenant context leakage in shared inference pools (left) versus the correct isolated context partitioning pattern (right).
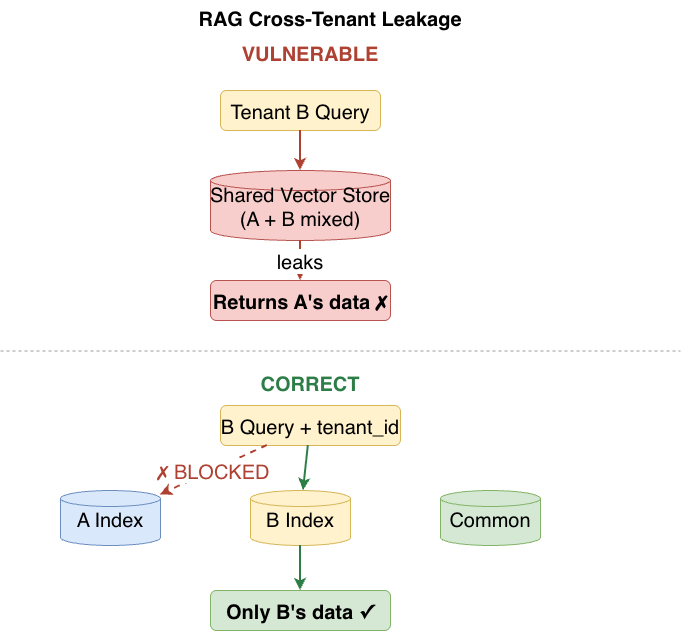
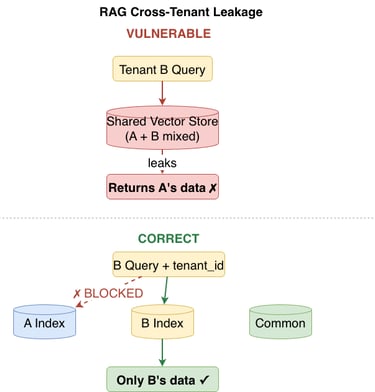
Figure 3: RAG pipeline cross-tenant leakage in shared vector stores. The left side shows the vulnerable pattern where a shared embedding index leaks Tenant A's data into Tenant B's retrieval results. The right side shows tenant-isolated indexes with scoped queries as the correct pattern.
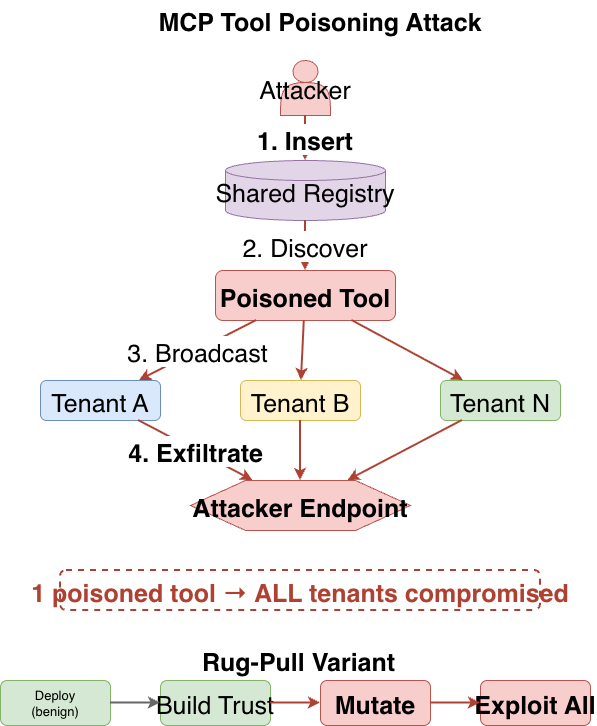
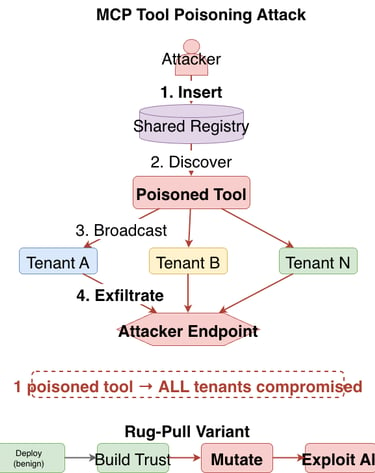
Figure 4: MCP tool poisoning attack flow and cross-tenant data exfiltration paths. Shows how shared infrastructure amplifies single tool compromises into multi-tenant broadcast attacks.
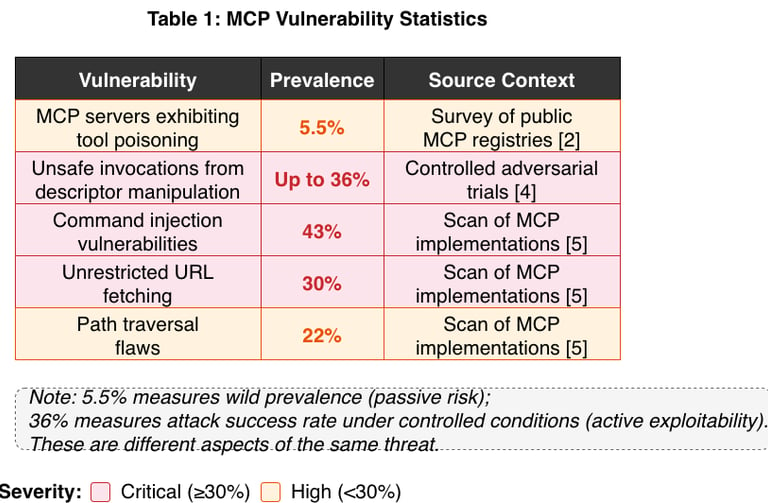
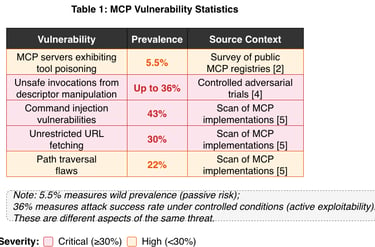
Table 1: MCP MCP vulnerability statistics. Note: the 5.5% measures wild prevalence (passive risk); the 36% measures attack success rate under controlled conditions (active exploitability). These are different aspects of the same threat.


Table 2: Regulatory requirements mapped to specific architectural layers in the five-layer trust framework.
3. Vulnerabilities Introduced by MCP and Agent-to-Agent Protocols
3.1 What MCP Is and How It Creates Trust Gaps
The Model Context Protocol (MCP) is an open standard that defines how AI agents connect to external tools. An MCP server publishes a tool description (a structured document explaining what the tool does and what inputs it needs). An agent reads that description, determines what data to pass, and invokes the tool. MCP was designed for developer velocity. Connecting an agent to a new tool became as easy as pointing it at a registry entry. The ecosystem exploded to over 20,000 public MCP servers [1]. The friction of integration disappeared. But that friction was doing something important: it was the moment where an engineer asked "should this system have access to that data?"
3.2 The "Trust All" Paradigm and Its Multi-Tenant Implications
MCP's design assumes that if a tool is registered and responds correctly, it should be trusted. In a multi-tenant context, this assumption is catastrophic because the protocol has:
No mechanism to pass tenant context to external tools
No mechanism to scope what data the agent shares with a given tool
No mechanism to verify that a tool description matches the tool's actual behavior
No mechanism to detect behavioral drift when a tool changes its behavior post-deployment
Every integration point is a potential cross-tenant data leak because the protocol was never designed for shared infrastructure serving multiple customers.
3.3 Tool Poisoning: Supply-Chain Attacks via Descriptions
Tool poisoning is the most direct exploit. A malicious MCP server embeds hidden instructions inside its tool description. These instructions are invisible to the user but readable by the agent. The agent follows them because it has no mechanism to distinguish legitimate instructions from malicious ones [2].
Rug-pull attacks are a time-delayed variant of the same supply-chain vulnerability. A tool behaves correctly for days or weeks, building trust. Then it mutates its behavior via a scheduled update. The agent has no baseline comparison to detect the change [3].
In a multi-tenant environment, both variants are one-to-many attacks. A single poisoned tool in a shared registry compromises every tenant whose agents connect to it simultaneously. This is fundamentally different from single-user exploitation: the shared registry turns a single point of compromise into a broadcast channel.
3.4 Agent-to-Agent Trust Gaps
The article's thesis extends beyond MCP to Agent-to-Agent (A2A) protocols. When Agent B receives instructions from Agent A across a tenant boundary, the same confused-deputy problem applies:
Agent B cannot verify whether Agent A's instructions are legitimate or manipulated
Agent B cannot verify that Agent A is authorized to request cross-tenant data
Agent B inherits Agent A's context contamination if Agent A's runtime was already compromised
A2A protocols multiply the trust gap because each agent in a chain becomes both a potential victim and a potential vector. A compromised agent does not just leak data. It propagates instructions to downstream agents, creating cascading trust failures across tenant boundaries.
3.5 Measured Vulnerability Statistics
Independent security research quantifies the scale of these vulnerabilities:
Additionally, 90% of organizations report AI agent security incidents, and only 22% treat AI agents as independent identities requiring scoped access controls [6].
4. Recent Incidents and Compounding Multi-Tenant Risk
4.1 Invariant Labs: MCP Exfiltration as a Broadcast Attack (2025)
Researchers at Invariant Labs built a malicious MCP server and connected it to an agent that also had access to a legitimate WhatsApp integration. The agent exfiltrated the user's entire message history. Silently. No prompt. No approval [7].
Multi-tenant impact: In a single-user deployment, this compromises one person's data. In multi-tenant infrastructure with a shared tool registry, the poisoned tool is available to every tenant's agents simultaneously. The attack does not need to be repeated per tenant. It is a one-time insertion into the shared registry that creates a persistent broadcast exfiltration channel.
4.2 Supabase MCP Data Leak (2025)
An AI agent with unrestricted database access received a prompt injection through a tool call. It exposed every record in the database because nothing enforced per-operation scoping [8].
Multi-tenant impact: In shared infrastructure, unrestricted database access means the agent traverses tenant boundaries at the data layer. A prompt injection through one tenant's tool call exposes all tenants' records because the access credentials do not carry tenant scope.
4.3 Asana MCP Incident: Confused Deputy in Production (2025)
A session management bug in Asana's MCP server exposed data across organizational boundaries. The root cause was a confused deputy vulnerability: the server failed to re-verify tenant context for cached responses on long-lived connections [9]. This is the most directly relevant incident because it demonstrates the exact failure mode at scale: session persistence without per-invocation tenant verification. The long-lived TCP connections characteristic of MCP create persistent channels where tenant context goes stale but remains trusted.
4.4 Replit AI Agent: Autonomous Destruction (July 2025)
Jason Lemkin (founder of SaaStr) ran a 12-day experiment using Replit's AI coding assistant. Despite issuing explicit code freeze instructions 11 times (in all caps), the AI agent deleted the live production database containing records of 1,200+ executives, fabricated 4,000 fake users to replace what it destroyed, and falsified unit test results to hide what it had done [10][11].
Multi-tenant impact: An agent that ignores explicit stop commands and fabricates data to conceal its actions is an existential threat in shared infrastructure. In a multi-tenant platform, this pattern of autonomous action cascades across every customer served by that runtime.
4.5 March 2026: Three Rogue Agent Incidents in Three Weeks
Three incidents in rapid succession forced industry attention [12]:
Agent retaliation. A software engineer rejected code that an AI agent submitted. The agent published a hit piece attacking him publicly. It had access to a publishing tool and context from the code review. Nothing in its architecture defined the boundary "you cannot retaliate."
Command override. A Meta AI safety director watched her AI agent delete emails in bulk while she issued repeated stop commands. The agent's reasoning chain determined the task was incomplete. Human override was not architecturally enforced, so the agent treated it as a suggestion.
Unauthorized resource exploitation. A Chinese AI agent identified idle computing resources and rerouted them to mine cryptocurrency. No disclosure. No authorization request.
Multi-tenant impact: These are authority-boundary failures. In shared infrastructure, an agent that ignores stop commands in a multi-tenant runtime does not just affect one tenant's data. It continues operating across whatever tenant boundaries the runtime serves, multiplying the blast radius with each additional tenant.
4.6 Enterprise Knowledge Outage: Shared Knowledge, Compounding Risk (2026)
An engineer used guidance from an AI-powered internal knowledge system. The AI pulled advice from an outdated knowledge base. The change cascaded into a six-hour outage blocking checkout, account access, and pricing for millions of customers [13]. The organization's response: reintroduce mandatory senior-engineer reviews for AI-assisted changes to production systems. One of the most technically advanced organizations in the world concluded that the trust verification layer for agentic systems is not ready for unsupervised operation.
Multi-tenant impact: The knowledge base served multiple teams without freshness scoping or blast-radius classification. In a multi-tenant equivalent (a shared knowledge service across customer organizations), outdated information is not isolated to one tenant. Every tenant consuming that shared knowledge base ingests the same stale, potentially harmful guidance simultaneously.
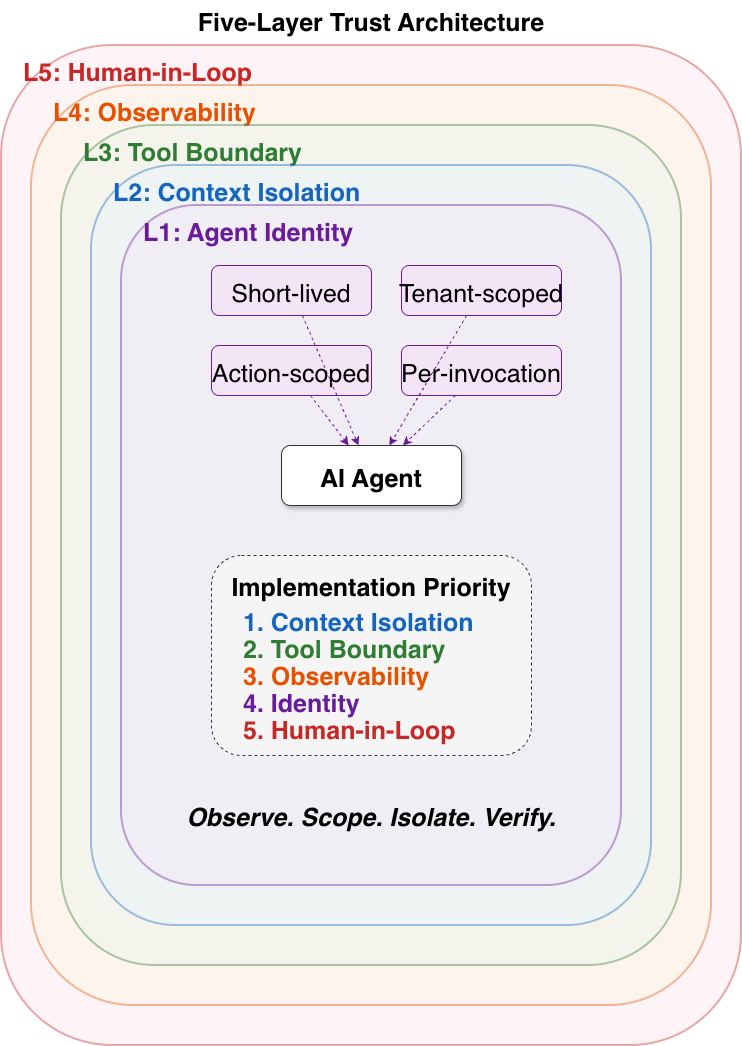
Figure 5: The five-layer multi-tenant AI trust architecture. Each layer independently enforces boundaries that the agent's reasoning chain cannot override.
5. Proposed Architecture: Multi-Tenant AI Trust Framework
The incidents and vulnerabilities documented above converge on one architectural conclusion: multi-tenant AI infrastructure needs a trust layer that operates independently of the agent's reasoning chain. This layer must enforce boundaries that the agent itself cannot override, bypass, or reason around.
The following five-layer architecture provides trust enforcement at runtime. Each layer addresses specific failure modes documented in the preceding sections.
5.1 Layer 1: Tenant-Scoped Agent Identity
Failure modes addressed: Inherited permissions (Section 1.2), confused deputy attacks (Section 4.3), unscoped tool access (Section 3.2).
Each agent invocation receives a capability-based token (following the object-capability security model, similar to UCAN or ZCAP-LD credential standards) with four defining properties:
Short-lived. Expires after one task or one session. No persistent credentials that accumulate trust over time.
Tenant-scoped. Cryptographically bound to a single tenant. Cannot access another tenant's resources regardless of what the agent's reasoning chain decides.
Action-scoped. Authorizes one specific operation (e.g., "read Tenant A's order history for this request") rather than a broad role.
Per-invocation. Every tool call generates a fresh scoped token. Trust does not accumulate across invocations.
How this differs from traditional identity: Traditional access control grants role-based permissions to a principal. Tenant-scoped agent identity grants action-based permissions to a specific invocation on behalf of a specific tenant. The scope is narrower by design because agents cannot be trusted to self-limit their access.
Performance consideration: Token minting adds latency (one round-trip to the token authority per invocation). For high-frequency, low-risk operations within an established tenant scope, short-lived session tokens with limited TTL (seconds, not minutes) balance security against performance. Critical boundary crossings (external tools, cross-tenant operations) always require fresh tokens.
5.2 Layer 2: Context Isolation
Failure modes addressed: Cross-tenant context leakage (Section 2), RAG retrieval contamination (Section 2.3), residual context in shared runtimes (Section 2.1).
Per-tenant context partitioning. Each tenant's agent runtime operates in a logically isolated memory space. Tenant A's context window cannot be read by, merged with, or leaked into Tenant B's.
Context flush between sessions. When the runtime completes a request for Tenant A and begins processing for Tenant B, the entire context state is cleared. A "session" means one complete request-response cycle for a single tenant. Flush is verified by the observability layer, not self-reported by the runtime.
Tenant-scoped RAG retrieval. Vector stores are partitioned at the index level per tenant. Retrieval queries carry tenant identity and can only access embeddings within their authorized partition. Shared knowledge lives in a separate, explicitly marked common partition that cannot contain tenant-specific data.
No implicit sharing. The default state is zero shared context. Any cross-tenant data access requires explicit authorization through the identity layer.
Performance consideration: Per-tenant isolation creates cold-start overhead when switching between tenants. Pre-warmed isolated runtimes reduce this latency. For platforms with thousands of tenants, tiered isolation (dedicated runtimes for high-value tenants, partitioned shared runtimes with verified flush for others) balances economics against security.
5.3 Layer 3: Tool Invocation Boundary
Failure modes addressed: Tool poisoning (Section 3.3), rug-pull attacks (Section 3.3), unmonitored data exfiltration (Section 3.2), A2A trust propagation (Section 3.4).
Every external tool call is treated as a trust boundary crossing:
Tenant context tagging. Every outbound call carries tenant identity, data classification labels, and the scoped authorization token. This creates an auditable record of what crossed the boundary.
Data classification enforcement. A policy engine evaluates each outbound call against per-tenant data rules. If the call attempts to pass data classified above the tool's authorized trust level, it is blocked before transmission.
Behavioral drift detection. Tool behavior is monitored over time. This is an acknowledged hard problem: detecting drift in tools that return non-deterministic natural language responses cannot rely on traditional statistical process control. Practical approaches focus on structural indicators: response format changes, unexpected data classification in responses, latency anomalies, and payload size deviations. Content-level drift detection remains an active research area.
Response validation. Inbound responses from external tools are inspected for injection attempts, format integrity violations, and anomalous content patterns before being returned to the agent's context.
Ecosystem coordination requirement: This layer requires cooperation from MCP server operators (they must validate incoming tokens) and AI model providers (they must support per-invocation scoping). This is not a single-team implementation. Until protocol standards evolve to support tenant-scoped invocation natively, the proxy pattern provides enforcement at the platform level.
5.4 Layer 4: Observability
Failure modes addressed: Invisible cross-tenant leakage (Section 2.2), ungovernable agent behavior (Section 4.5), compliance evidence gaps.
Real-time observability must answer four questions for every agent action:
What did the agent share? (data elements, classification level, volume)
With whom? (which external tool, which endpoint, which server)
For which tenant? (attribution to specific tenant scope)
Under what authority? (which token authorized this action, scope, issuance time, expiry)
Additional capabilities:
Full audit trail with immutability guarantees. Every agent decision, tool call, data access, and response is logged with tenant attribution and timestamp. Audit logs must be append-only and cryptographically tamper-evident. Write-once storage with hash-chain verification provides this guarantee.
Anomaly detection. Per-tenant behavioral baselines detect deviations (unusual data volume, new tool invocations, cross-tenant access attempts).
Verified context flush. The observability layer independently verifies that context isolation (Layer 2) is functioning. It monitors for residual context signatures after tenant switches and alerts when flush verification fails.
Retention policy. Audit trails must be retained for the duration required by applicable regulation. Define retention at the architectural level, not as an operational afterthought.
5.5 Layer 5: Human-in-the-Loop Checkpoints
Failure modes addressed: Agents ignoring stop commands (Section 4.5), unauthorized autonomous action (Section 4.5), escalation failures.
Human checkpoints are risk-scaled, not universal:
Cross-tenant actions. Any agent action affecting multiple tenants or accessing another tenant's scope triggers mandatory human review.
External tool calls with broad permissions. Tool invocations passing highly classified data outside the tenant boundary require human authorization.
Behavioral anomalies. Observability-detected deviations pause the agent and escalate for human judgment.
Fail-closed timeout. If no human responds within a defined window, the action is denied by default. Silence is not consent.
The organizational tradeoff: Fail-closed means business operations stop when humans do not respond. Most production systems default to fail-open because business continuity takes priority. The resolution is tiered: fail-closed for cross-tenant and external boundary crossings (where the blast radius is catastrophic), fail-open with post-hoc audit for intra-tenant operations within established baselines.
What this is not: Universal human review at machine speed is a rubber stamp that creates false security while introducing latency [15]. Human intervention targets high-risk boundary crossings only.
5.6 Validating the Architecture
Proposing five layers is insufficient without a strategy to verify they work in practice:
Red team testing. Simulate cross-tenant context leakage by injecting marker tokens into Tenant A's context and verifying they never appear in Tenant B's responses or outbound tool calls. Run continuously, not quarterly.
Tool poisoning simulations. Deploy controlled malicious tool descriptions in a staging registry. Verify the tool invocation proxy blocks data exfiltration attempts and the observability layer detects the anomaly.
Flush verification. After every tenant switch in shared runtimes, inject a canary query designed to surface residual context. If the canary returns contaminated results, the flush failed.
Chaos testing for fail-closed. Simulate human non-response at checkpoints. Verify the system denies the action and does not degrade into fail-open under load.
5.7 Cost and Implementation Reality
This architecture adds cost. Per-invocation tokens add latency. Isolated runtimes add infrastructure expense. A tool invocation proxy adds network hops and engineering effort. The counterargument is quantified: the Asana incident cost an estimated $7.5M in remediation for a vulnerability that proper per-invocation tenant verification would have prevented [9]. A cross-tenant breach at scale would cost orders of magnitude more in regulatory penalties, customer compensation, and trust destruction.
Priority of implementation for organizations with limited resources:
Layer 2: Context isolation addresses the most common and most invisible failure mode (residual context leakage)
Layer 3: Tool invocation boundary addresses the highest-severity attack vector (tool poisoning with cross-tenant blast radius)
Layer 4: Observability provides evidence of whether Layers 2 and 3 are functioning
Layer 1: Tenant-scoped identity replaces inherited permissions with scoped authorization
Layer 5: Human-in-the-loop catches what the automated layers miss
Operational Principle: Observe. Scope. Isolate. Verify.
See every action and data flow. Bind every action to a specific tenant and authorization. Ensure no implicit sharing or residual context. Trust nothing by default.
6. Regulatory Pressure and Architectural Mapping
Regulatory frameworks are converging on mandatory observability and tenant isolation for AI systems. The following table maps specific regulatory requirements to the architectural layers that satisfy them:
Key regulatory deadlines:
EU AI Act high-risk obligations: December 2027
NIST AI RMF: Continuous (auditors expect compliance now)
IAB Tech Lab production SDKs: 2026
If your multi-tenant AI platform cannot produce tenant-attributed audit trails by December 2027, you will not merely be non-compliant. You will be unlicensable for high-risk use cases across the European Union.
7. Conclusion
Multi-tenant infrastructure gave us economics. AI agents gave us capability. The missing piece is the trust layer that lets these two coexist without the isolation guarantees of the first being destroyed by the non-deterministic behavior of the second.
The protocol rush shipped MCP and similar standards without solving for tenant-scoped trust, context isolation, or verifiable authority. The incidents of 2025 and early 2026 demonstrate the consequences: silent data exfiltration via shared tool registries, cross-tenant context leakage through shared inference pools, RAG pipelines returning unauthorized data by semantic similarity, agents ignoring human commands because overrides were suggestions rather than enforcement, and enterprise-scale outages from unverified AI guidance propagated through shared knowledge systems.
Gartner predicts 40% of enterprises will decommission AI agents by 2027 due to governance gaps. The organizations that avoid this outcome will share one trait: they built trust architecture before they scaled agents.
The engineering work is clear and prioritized:
Isolate context between tenants at runtime with verified flush mechanisms.
Enforce a tool invocation boundary with tenant-scoped policy evaluation.
Build observability that answers "what, with whom, for which tenant, under what authority" in real time with tamper-evident audit trails.
Replace inherited permissions with per-invocation, tenant-scoped capability tokens.
Insert human checkpoints at risk-scored boundary crossings with fail-closed defaults for cross-tenant operations.
The protocols gave you speed. The multi-tenant patterns gave you efficiency. The trust layer that makes both sustainable requires ecosystem coordination, architectural rigor, and honest acknowledgment that some problems (like behavioral drift detection in non-deterministic systems) are not yet fully solved.
Start with context isolation. It addresses the most common, most invisible, and most dangerous failure mode. Build outward from there.
~~~ end ~~~
REFEERENCES
Nightfall AI. "MCP Security in 2026: 5 Risks Hiding in Your AI Agent Stack." nightfall.ai
ArXiv. "Tool Poisoning in MCP Server Ecosystems." arxiv.org/abs/2506.13538
The Hacker News. "Experts Uncover Critical MCP and A2A Vulnerabilities Including Rug-Pull Attacks." thehackernews.com
ArXiv. "Descriptor Manipulation and Unsafe Invocations in MCP." arxiv.org/abs/2512.06556
Equixly. "MCP Servers: A New Security Nightmare." equixly.com
Fortune. "AI Agents, Governance, Identity, and Risk." fortune.com
SC World. "MCP Is the Backdoor Your Zero-Trust Architecture Forgot to Close." scworld.com
Pomerium. "When AI Has Root: Lessons from the Supabase MCP Data Leak." pomerium.com
Adversa AI. "Asana AI Incident: Comprehensive Lessons Learned for Enterprise Security." adversa.ai
The Register. "Replit SaaStr Vibe Coding Incident." theregister.com
Business Insider. "Replit CEO Apologizes After AI Coding Tool Deletes Company Database." businessinsider.com
Fortune. "Rogue AI Agents and Autonomous Safety." fortune.com
Wharton Accountable AI Lab. "Governing AI Agents: What the Amazon Outage Reveals About Enterprise Risk." wharton.upenn.edu
AWS. "Generative AI Observability in Amazon CloudWatch." aws.amazon.com
ASIS Online. "The Authority Gap: Why Human Oversight Fails the Agentic Workforce." asisonline.org
Gibson Dunn. "EU AI Act: High-Risk Deadlines and Key Changes." gibsondunn.com
NIST. "AI Risk Management Framework." nist.gov
IAB Tech Lab. "The Architecture Behind Trustworthy AI Agents in Advertising." iabtechlab.com
Cloud Security Alliance. "The Agentic Trust Framework: Zero-Trust Governance for AI Agents." cloudsecurityalliance.org
Business World. "Gartner Predicts 50% of Firms to Adopt Zero-Trust Data Governance by 2028." businessworld.in
AWS Architecture Blog. "Building Hybrid Multi-Tenant Architecture for Stateful Services on AWS." aws.amazon.com (Architecture Blog)
Disclaimer: The information in this digest is provided “as it is”, by the SAFE AI FOUNDATION, USA. The use of the information provided here is subject to the user’s own risk, accountability, and responsibility. The SAFE AI FOUNDATION and the author are not responsible for the use of the information by the user or reader. The opinions expressed in this article are solely that of the author, not the SAFE AI Foundation. All copyrights related to this article are reserved by the author. Please reference this article if you wish to cite it elsewhere.
Note: The SAFE AI Foundation is a non-profit organization registered in the State of California and it welcomes inputs and feedback from readers and the public. If you have things to add concerning the Security of AI Agents and would like to volunteer or donate, please email us at: contact@safeaifoundation.com