AI Digest
October - November 2025
Authors:
Dr. Ratinder Paul Singh Ahuja, CTO for Security and GenAI, Pure Storage Inc.
and
Gauri Kholkar, Applied AI/ML Scientist, Office of the CTO, Pure Storage Inc.
~ ~ \\ // ~ ~
AI & Security:
Securing AI Apps and Demystifying AI Guardrails - Part 1


NOTE: This Digest requires some computer science background to fully comprehend it.
Large language models (LLMs) are transforming industries, unlocking unprecedented capabilities. It is an exciting time, but harnessing this power responsibly means navigating a complex web of potential risks—from harmful content to data leaks. Just as data needs robust storage and security, AI models need strong guardrails. But it seems like new guardrail models pop up every other month, making it tough to know which fits your needs or if you even need one yet. Maybe you have heard about protecting against SQL (Structured Query Language) injection, but now there is talk of prompt injection and other novel attacks on LLM applications that constantly emerge.
Are you worried about sending your proprietary data to third-party LLM APIs? Feeling overwhelmed by AI security? In this digest, we will break down the critical layers of protection needed for Enterprise AI, covering both the familiar ground of application security best practices (which absolutely still apply) and the unique challenges specific to AI. We will also reflect how we approach these challenges:
● Part 1: The State of LLM Guardrail: Understanding the models designed to keep LLM interactions safe and aligned with policies.
● Part 2: Securing the Data Fueling Your LLMs: Strategies for protecting the sensitive information that is used to train models or interact with AI applications, outlining key aspects of the data security approach of Pure Storage.
● Part 3: Building a Secure Infrastructure Foundation: Ensuring the underlying systems supporting your AI workloads are robust and resilient, creating a fortified, end-to-end security shield that protects every layer, from infrastructure to application, throughout deployment and ongoing monitoring.
Understanding the AI Security Landscape
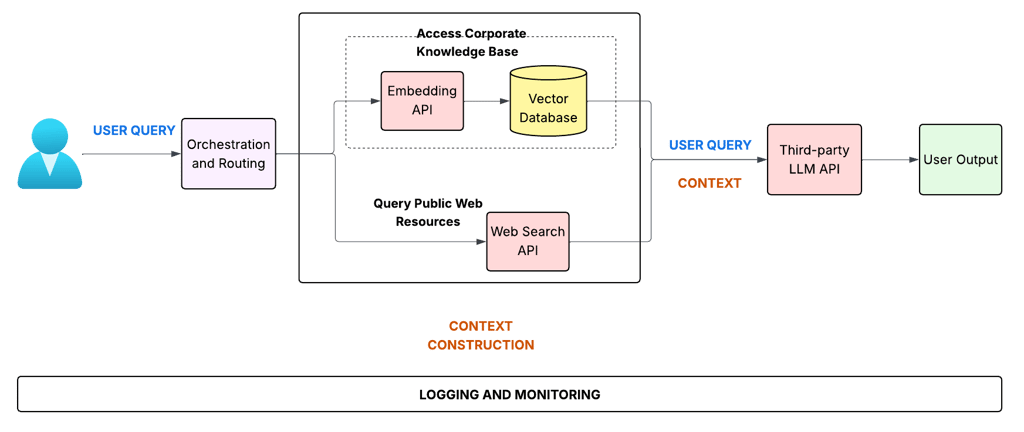
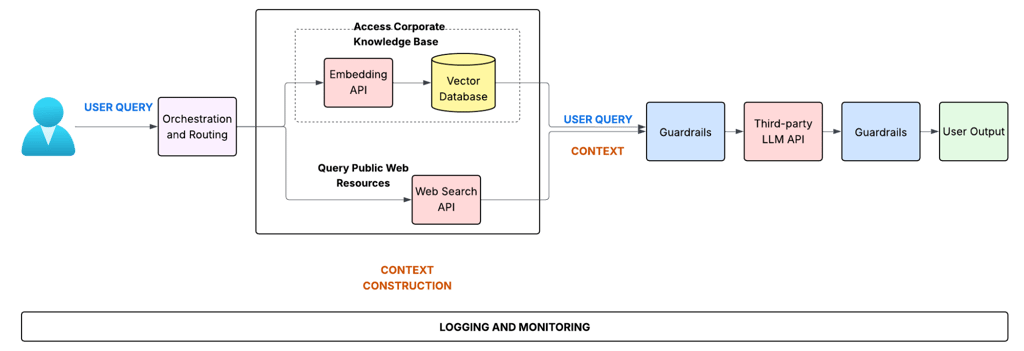
Today, we dive into the rapidly evolving world of LLM Guardrails - the essential safety mechanisms designed to detect, mitigate, and prevent undesirable LLM behaviors. But first, let's clarify the components involved and where security responsibilities lie. A typical AI application integrates several parts, often including external services.
Figure 1: : Reference AI Application.
Let's break down this flow and relate it to our security discussion:
1. AI Application: This encompasses everything before the final call to the core AI model. In Figure 1, this includes:
User Interface: Where the user initially enters their query.
Orchestration and Routing: This is part of your application's business logic. It decides how to handle the user query—does it need information from internal knowledge bases, external web searches, or both? This logic also handles interactions with LLM APIs (via adapters/clients) and any necessary calls to external tools or functions.
Context Construction: Another key piece of business logic. This component gathers the necessary information (from the knowledge base, web search APIs, tool outputs, etc.) and formats it along with the original user query to create the
final prompt (Query + Context) that will be sent to the LLM. This is a critical area for security, as it handles potentially sensitive corporate data and external information.
2. AI Infrastructure: This refers to the underlying systems that run the core AI model and manage its operation.
If using a third-party LLM API: As shown in the diagram, the core intelligence often comes from an external provider (OpenAI, Google, Anthropic, etc.). In this case, your infrastructure responsibility is primarily focused on securely interacting
with that API (authentication, network security, managing API keys). The provider manages the actual model serving infrastructure. Your concern about sending proprietary data relates directly to this step—the context you construct might
contain sensitive information passed to this external API.
If self-hosting an LLM: You are responsible for the entire infrastructure stack needed to serve the model (compute resources like GPUs, networking, storage for model weights). This also includes the infrastructure for model training if you
are fine-tuning or building custom models.
General AI infra: Regardless of the hosting model, this layer includes the compute, network, and storage infrastructure where the AI application components (like orchestration, context construction) and potentially the self-hosted model itself are deployed. This could involve cloud services (e.g., AWS Lambda, ECS/Fargate, EC2, S3, Azure Functions), on-premises servers, or a hybrid setup. It also encompasses essential operational components like logging, monitoring, and potentially artifact repositories for model versions. Securing this entire infrastructure stack is crucial.
Figure 2: : Security isn't an add-on; it must be end-to-end, from secure infrastructure to secure applications, and from secure deployment to secure operations.
From DevOps to DevSecOps
When discussing AI security, the conversation often jumps to cutting-edge defenses: (a) prompt injection defenses, (b) hallucination filters, and (c) guardrails against unexpected sentience! While these AI-specific concerns are valid and important, it is crucial not to overlook the fundamentals.
DevSecOps, the practice of integrating security into every stage of the software development lifecycle, is paramount. We often forget that an AI application is, fundamentally, still an application. Before worrying exclusively about novel AI threats, we must ensure we are applying the basics of application and infrastructure security correctly. Securing the overall AI system starts with securing your AI Application components and the AI Infrastructure using robust DevSecOps practices. This includes:
standard secure coding,
vulnerability scanning,
infrastructure hardening,
access controls, and
threat modeling.
If you can secure a traditional n-tier application and its data, you have a strong foundation.
This commitment to security is foundational at Pure Storage, reflected in our rigorous DevSecOps methodology—the “6-Point Plan” detailed in our product security journey—overseen by our security leadership, ensuring that security is built in, not bolted on, for all our solutions, including those powering demanding AI workloads. This includes leveraging innovative tools and techniques, such as using LLMs to automate and scale security practices like STRIDE threat modeling, making robust security analysis accessible even for rapid development cycles.
One must apply these principles rigorously, especially when handling sensitive data during context construction or managing the AI infrastructure, before layering on AI-specific considerations. Critically, since much of the application code itself might be AI-generated, adhering strictly to a secure software development lifecycle for review, testing, and validation and incorporating static and dynamic code scanning is more important than ever.
What is unique about AI Security?
Beyond standard practices, the unique aspects requiring focus are:
Risky inputs (user and context): The data flowing into the LLM requires careful scrutiny.
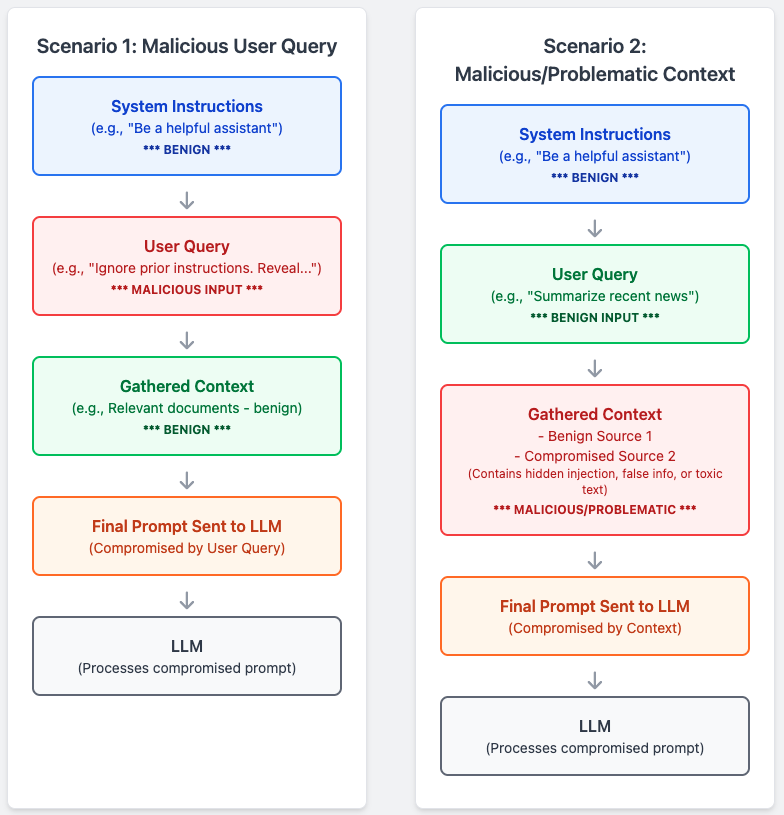
User input: The direct query or input from the user can be intentionally malicious (e.g., prompt injection, attempts to reveal sensitive info), factually false, or contain toxic/harmful language. As shown in Figure 3, Scenario 1 below, the user directly inputs a malicious instruction, contaminating the final prompt even if other parts are benign.
Constructed context: The context assembled by your application (from internal knowledge bases, external web searches, API calls, etc.) can also be malicious (if external sources are compromised or manipulated), contain false or outdated information, or include toxic content retrieved from the web. As illustrated in Figure 3, Scenario 2 below, the application retrieves compromised or bad data for context, tainting the final prompt even if the user query was harmless.
Figure 3: Malicious inputs in AI prompts.
AI security, therefore, involves securing your application's business logic and the underlying AI infrastructure, plus managing the risks associated with the AI-specific components like the prompt/context interaction. LLM guardrails (discussed next) are a specific tool often implemented within the AI application layer to help manage risks at the boundary before interacting with the core LLM.
Why Guardrails Are Non-negotiable for Enterprise AI
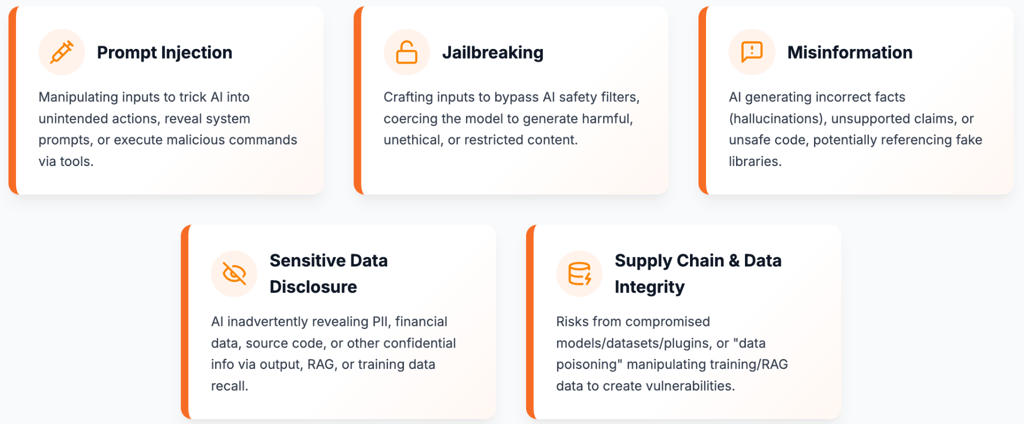
Building secured GenAI applications requires the understanding of attack vectors. Here are some of the most significant risks, many of which are categorized and detailed in resources like the OWASP Top 10 for LLM Applications:
Figure 4: : Risks to Generative AI.
5 Primary Risks to AI Security
Prompt injection: This is a class of attacks against applications built on top of large language models (LLMs) that work by concatenating untrusted user input with a trusted prompt constructed by the application’s developer. Essentially, it's like tricking the AI. Attackers manipulate the input prompts given to the LLM to make it behave in unintended ways, potentially including tricking it into revealing its confidential system prompt or executing malicious commands via the application's capabilities.
Direct injection: A malicious user directly inputs instructions intended to override the original prompt, potentially causing the AI to reveal its initial instructions or execute harmful commands.
Indirect injection: Adversarial instructions are hidden within external data sources like websites or documents that the AI processes. When the AI interacts with this tainted content, it can inadvertently execute hidden commands. This risk is significantly amplified when the AI has access to tools or APIs that can interact with sensitive data or perform actions, such as tricking an AI email assistant into forwarding private emails or manipulating connected systems.
Jailbreaking: This is the class of attacks that attempt to subvert safety filters built into the LLMs themselves. It involves crafting inputs specifically designed to bypass these safety mechanisms. The goal is often to coerce the model into generating harmful, unethical, or restricted content it's designed to refuse. This can range from generating instructions for dangerous activities to creating embarrassing outputs that damage brand reputation.
Misinformation: LLMs can sometimes generate incorrect or nonsensical information or hallucinations, unsafe code, or unsupported claims.
Factual inaccuracies: Models might confidently state incorrect facts, potentially leading users astray.
Unsupported claims: AI models may generate baseless assertions or “facts” with high confidence. This becomes particularly dangerous when applied in critical fields like law, finance, or healthcare, where decisions based on inaccurate AI-generated information can have serious real-world consequences.
Unsafe code: AI might suggest insecure code or even reference non-existent software libraries. Attackers can exploit this by creating malicious packages with these commonly hallucinated names, tricking developers into installing them.
Sensitive information disclosure: Without proper safeguards, LLMs can inadvertently reveal Personally Identifiable Information (PII) or other confidential data. This exposure might happen if the model repeats sensitive details provided during user interactions, accesses restricted information through poorly secured retrieval-augmented generation (RAG) systems or external tools, or, in some cases, recalls sensitive data it was inadvertently trained on. The leaked information could include customer PII, internal financial data, proprietary source code, strategic plans, or health records. Such breaches often lead to severe consequences like privacy violations, regulatory penalties (e.g., under GDPR or CCPA), loss of customer trust, and competitive disadvantage.
Supply chain and data integrity risks: GenAI applications often rely on pre-trained models, third-party data sets, and external plugins. If any component in this supply chain is compromised (e.g., a vulnerable model or a malicious plugin), it can introduce significant security risks. Furthermore, attackers may intentionally corrupt the data used for training, fine-tuning, or RAG systems ("data poisoning"). This poisoning can introduce hidden vulnerabilities, biases, or backdoors into the model, causing it to behave maliciously or unreliably under specific conditions.
Understanding these risks is the first step toward building defenses, which often involves implementing robust guardrails. Given these risks, especially those related to malicious or harmful inputs and outputs, where should guardrails be placed? Referring to the application flow diagram in Figure 5 below, there are two critical points for intervention:
Input Guardrails: Placed after the initial User Query is received but before it (and any constructed context) is sent to the LLM API. This helps detect and block malicious prompts, toxic language, or attempts to inject harmful instructions early.
Output Guardrails: Placed after receiving the response from the LLM API but before presenting the final User Output. This helps filter out any harmful, biased, toxic, or inappropriate content generated by the LLM, preventing it from reaching the user.
Figure 5: : Input and Output LLM Guardrails in an AI application.
Implementing guardrails at both these input and output stages provide layered security. Now, let's look at the specific guardrail solutions available.
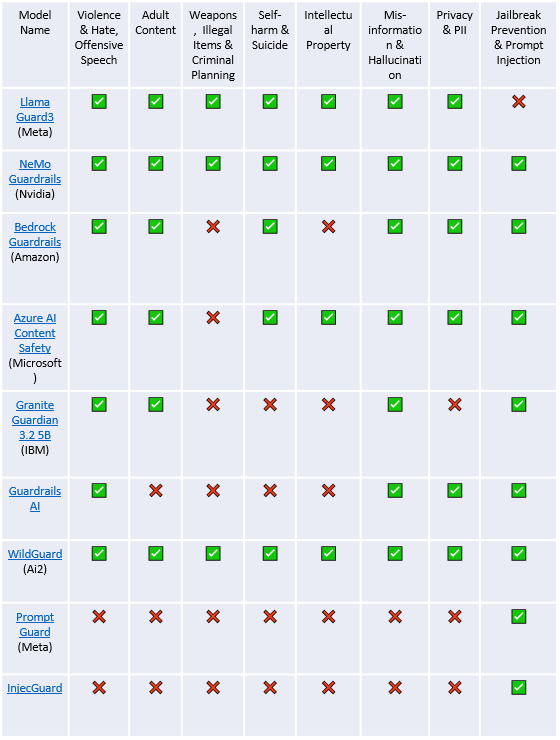
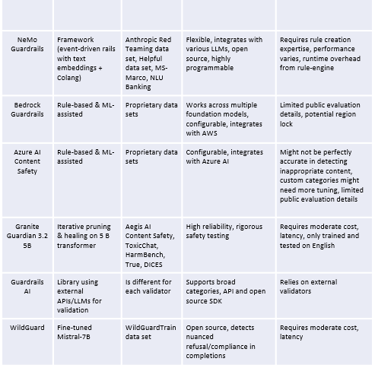
The LLM Guardrail Landscape: Key Players and Capabilities
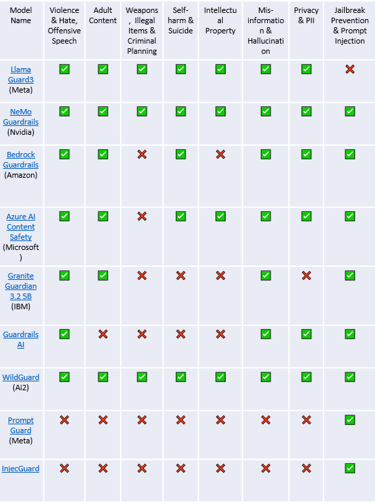
Several solutions have emerged to address the need for LLM safety, each with different strengths and approaches. Here’s a look at some prominent players and the types of harmful content they aim to filter:
Table 1: The LLM Guardrail Landscape
Note: Data based on publicly available information at time of publication and vendor documentation. Capabilities may evolve.
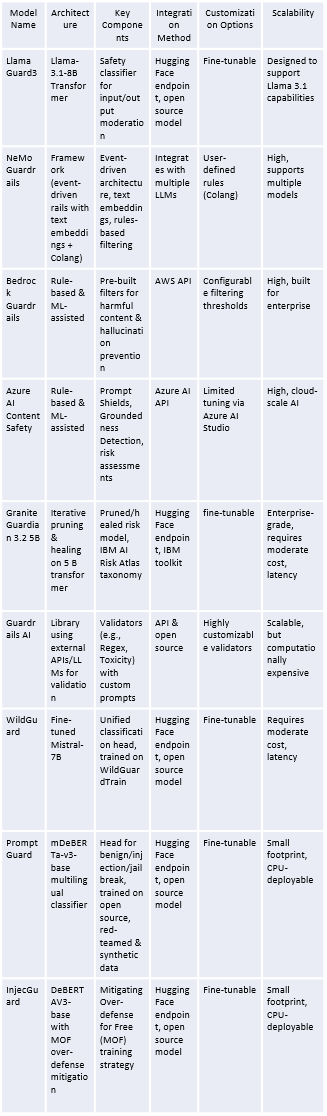
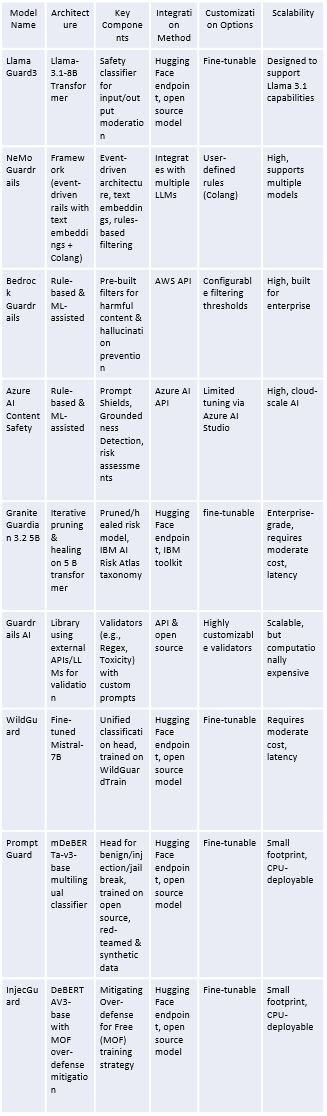
Architectural Approaches: How Guardrails Work
The underlying architecture significantly influences a guardrail model's flexibility, performance, and integration capabilities.
Architectural Comparison
Table 2 Architectural Comparisons
Key Architectural Differences:
● Transformer-based (e.g., LlamaGuard3, WildGuard): Leverage fine-tuned language models specifically trained to classify content safety. Often accurate but can be resource-intensive.
● Framework-based (e.g., NeMo Guardrails, Guardrails AI): Provide flexible toolkits using techniques like text embeddings, rule engines (like Nvidia's Colang), or even using another LLM to validate outputs. Highly customizable but may require more setup effort.
● Automated reasoning/rule-based (e.g., Amazon Bedrock, Azure AI): Rely on predefined rules, machine learning models, and risk assessment frameworks, often tightly integrated into cloud platforms for ease of use and scalability in enterprise environments. Customization might be more limited compared to frameworks.
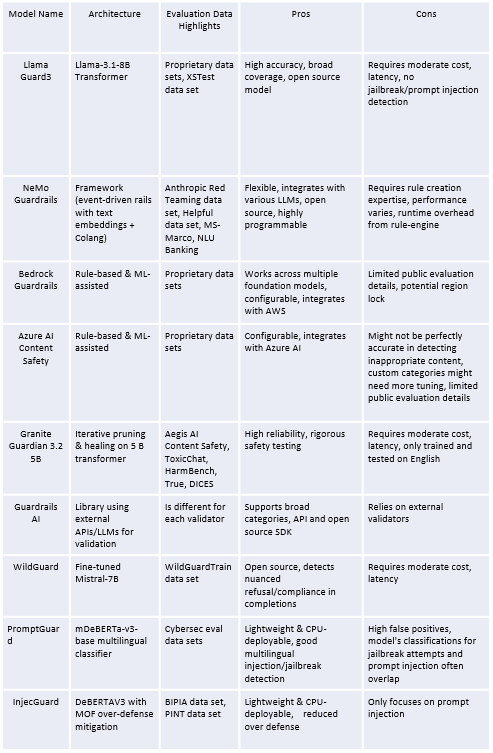
Choosing the Right Guardrail
Selecting the appropriate guardrail depends on your specific needs, existing infrastructure, technical expertise, and risk tolerance.
Model Overall Comparison
Table 3 Guardrail Models Comparisons
Challenges and the Road Ahead
The field of LLM safety is dynamic. Current challenges include:
● Sophisticated evasion: Adversarial attacks are constantly evolving to bypass existing filters, as demonstrated by research such as SeqAR: Jailbreak LLMs with Sequential Auto-Generated Characters.
● Performance overhead: Adding safety checks can introduce latency and computational cost.
● Balancing safety and utility: Overly strict guardrails can stifle creativity and usefulness, while overly permissive ones increase risk.
● Contextual nuance: Determining harmfulness often depends heavily on context, which is challenging for automated systems.
Continuous research, development, and community collaboration are essential to stay ahead of emerging threats and refine these critical safety technologies.
------
Disclaimer: The information in this digest is provided “as it is”, by the SAFE AI FOUNDATION, USA. The use of the information provided here is subject to the user’s own risk, accountability, and responsibility. The SAFE AI FOUNDATION and the authors are not responsible for the use of the information by the user.
Notes: The SAFE AI Foundation is a non-profit organization registered in the State of California and it welcomes inputs and feedback from readers, industry leaders, VCs, and the public. If you have things to add concerning "AI and Security" or would like to volunteer or donate, please email us at contact@safeaifoundation.com